
![]()
The Google Professional-Machine-Learning-Engineer Questions & Practice Test are Available On-Demand
Valid Professional-Machine-Learning-Engineer Exam Dumps Ensure you a HIGH SCORE
The Google Professional Machine Learning Engineer certification is a highly valuable qualification for professionals who are looking to advance their career in the field of machine learning. The certification demonstrates that the candidate has the necessary skills and expertise to design, build, and deploy highly scalable and efficient machine learning solutions using Google Cloud's machine learning tools and services. The exam tests the candidate's knowledge of key machine learning concepts, performance-based tasks, and case studies that evaluate the candidate's ability to design and implement machine learning solutions.
NEW QUESTION # 22
A data scientist has developed a machine learning translation model for English to Japanese by using Amazon SageMaker's built-in seq2seq algorithm with 500,000 aligned sentence pairs. While testing with sample sentences, the data scientist finds that the translation quality is reasonable for an example as short as five words. However, the quality becomes unacceptable if the sentence is 100 words long.
Which action will resolve the problem?
- A. Change preprocessing to use n-grams.
- B. Choose a different weight initialization type.
- C. Add more nodes to the recurrent neural network (RNN) than the largest sentence's word count.
- D. Adjust hyperparameters related to the attention mechanism.
Answer: C
NEW QUESTION # 23
You work on a data science team at a bank and are creating an ML model to predict loan default risk. You have collected and cleaned hundreds of millions of records worth of training data in a BigQuery table, and you now want to develop and compare multiple models on this data using TensorFlow and Vertex AI. You want to minimize any bottlenecks during the data ingestion state while considering scalability. What should you do?
- A. Convert the data into TFRecords, and use tf.data.TFRecordDataset() to read them.
- B. Use the BigQuery client library to load data into a dataframe, and use tf.data.Dataset.from_tensor_slices() to read it.
- C. Use TensorFlow I/O's BigQuery Reader to directly read the data.
- D. Export data to CSV files in Cloud Storage, and use tf.data.TextLineDataset() to read them.
Answer: D
NEW QUESTION # 24
You have deployed multiple versions of an image classification model on Al Platform. You want to monitor the performance of the model versions overtime. How should you perform this comparison?
- A. Compare the mean average precision across the models using the Continuous Evaluation feature
- B. Compare the loss performance for each model on the validation data
- C. Compare the loss performance for each model on a held-out dataset.
- D. Compare the receiver operating characteristic (ROC) curve for each model using the What-lf Tool
Answer: B
NEW QUESTION # 25
A Machine Learning Specialist receives customer data for an online shopping website. The data includes demographics, past visits, and locality information. The Specialist must develop a machine learning approach to identify the customer shopping patterns, preferences, and trends to enhance the website for better service and smart recommendations.
Which solution should the Specialist recommend?
- A. Collaborative filtering based on user interactions and correlations to identify patterns in the customer database.
- B. Random Cut Forest (RCF) over random subsamples to identify patterns in the customer database.
- C. Latent Dirichlet Allocation (LDA) for the given collection of discrete data to identify patterns in the customer database.
- D. A neural network with a minimum of three layers and random initial weights to identify patterns in the customer database.
Answer: A
Explanation:
Explanation
NEW QUESTION # 26
You are an ML engineer at a mobile gaming company. A data scientist on your team recently trained a TensorFlow model, and you are responsible for deploying this model into a mobile application. You discover that the inference latency of the current model doesn't meet production requirements. You need to reduce the inference time by 50%, and you are willing to accept a small decrease in model accuracy in order to reach the latency requirement. Without training a new model, which model optimization technique for reducing latency should you try first?
- A. Model distillation
- B. Weight pruning
- C. Dimensionality reduction
- D. Dynamic range quantization
Answer: A
NEW QUESTION # 27
A monitoring service generates 1 TB of scale metrics record data every minute. A Research team performs queries on this data using Amazon Athena. The queries run slowly due to the large volume of data, and the team requires better performance.
How should the records be stored in Amazon S3 to improve query performance?
- A. Compressed JSON
- B. Parquet files
- C. CSV files
- D. RecordIO
Answer: B
NEW QUESTION # 28
Your team has been tasked with creating an ML solution in Google Cloud to classify support requests for one of your platforms. You analyzed the requirements and decided to use TensorFlow to build the classifier so that you have full control of the model's code, serving, and deployment. You will use Kubeflow pipelines for the ML platform. To save time, you want to build on existing resources and use managed services instead of building a completely new model. How should you build the classifier?
- A. Use an established text classification model on Al Platform to perform transfer learning
- B. Use the Natural Language API to classify support requests
- C. Use AutoML Natural Language to build the support requests classifier
- D. Use an established text classification model on Al Platform as-is to classify support requests
Answer: A
Explanation:
the model cannot work as-is as the classes to predict will likely not be the same; we need to use transfer learning to retrain the last layer and adapt it to the classes we need
NEW QUESTION # 29
You have trained a deep neural network model on Google Cloud. The model has low loss on the training data, but is performing worse on the validation dat a. You want the model to be resilient to overfitting. Which strategy should you use when retraining the model?
- A. Run a hyperparameter tuning job on Al Platform to optimize for the learning rate, and increase the number of neurons by a factor of 2.
- B. Run a hyperparameter tuning job on Al Platform to optimize for the L2 regularization and dropout parameters
- C. Apply a L2 regularization parameter of 0.4, and decrease the learning rate by a factor of 10.
- D. Apply a dropout parameter of 0 2, and decrease the learning rate by a factor of 10
Answer: C
Explanation:
Applying a L2 regularization parameter of 0.4 and decreasing the learning rate by a factor of 10 can help to reduce overfitting and make the model more resilient. Source: Google Cloud
NEW QUESTION # 30
You are creating a deep neural network classification model using a dataset with categorical input values. Certain columns have a cardinality greater than 10,000 unique values. How should you encode these categorical values as input into the model?
- A. Convert each categorical value into a run-length encoded string.
- B. Convert the categorical string data to one-hot hash buckets.
- C. Convert each categorical value into an integer value.
- D. Map the categorical variables into a vector of boolean values.
Answer: D
NEW QUESTION # 31
Your organization's call center has asked you to develop a model that analyzes customer sentiments in each call. The call center receives over one million calls daily, and data is stored in Cloud Storage. The data collected must not leave the region in which the call originated, and no Personally Identifiable Information (Pll) can be stored or analyzed. The data science team has a third-party tool for visualization and access which requires a SQL ANSI-2011 compliant interface. You need to select components for data processing and for analytics. How should the data pipeline be designed?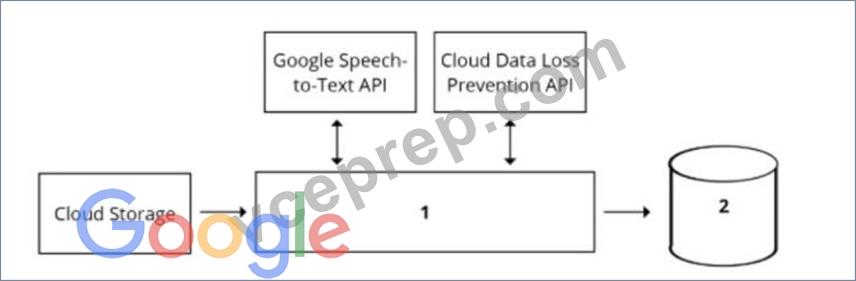
- A. 1 = Dataflow, 2 = Cloud SQL
- B. 1 = Cloud Function, 2 = Cloud SQL
- C. 1 = Dataflow, 2 = BigQuery
- D. 1 = Pub/Sub, 2 = Datastore
Answer: D
NEW QUESTION # 32
You need to train a natural language model to perform text classification on product descriptions that contain millions of examples and 100,000 unique words. You want to preprocess the words individually so that they can be fed into a recurrent neural network. What should you do?
- A. Assign a numerical value to each word from 1 to 100,000 and feed the values as inputs in your model.
- B. Sort the words by frequency of occurrence, and use the frequencies as the encodings in your model.
- C. Create a hot-encoding of words, and feed the encodings into your model.
- D. Identify word embeddings from a pre-trained model, and use the embeddings in your model.
Answer: D
NEW QUESTION # 33
Your team is working on an NLP research project to predict political affiliation of authors based on articles they have written. You have a large training dataset that is structured like this: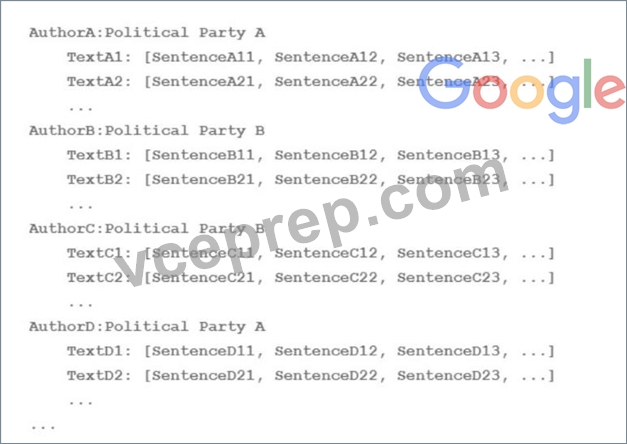
A)
B)
C)
D)
- A. Option A
- B. Option D
- C. Option C
- D. Option B
Answer: C
NEW QUESTION # 34
You need to analyze user activity data from your company's mobile applications. Your team will use BigQuery for data analysis, transformation, and experimentation with ML algorithms. You need to ensure real-time ingestion of the user activity data into BigQuery. What should you do?
- A. Configure Pub/Sub to stream the data into BigQuery.
- B. Configure Pub/Sub and a Dataflow streaming job to ingest the data into BigQuery,
- C. Run an Apache Spark streaming job on Dataproc to ingest the data into BigQuery.
- D. Run a Dataflow streaming job to ingest the data into BigQuery.
Answer: A
NEW QUESTION # 35
Which of the following metrics should a Machine Learning Specialist generally use to compare/evaluate machine learning classification models against each other?
- A. Area Under the ROC Curve (AUC)
- B. Recall
- C. Mean absolute percentage error (MAPE)
- D. Misclassification rate
Answer: A
NEW QUESTION # 36
While performing exploratory data analysis on a dataset, you find that an important categorical feature has 5% null values. You want to minimize the bias that could result from the missing values. How should you handle the missing values?
- A. Remove the rows with missing values, and upsample your dataset by 5%.
- B. Move the rows with missing values to your validation dataset.
- C. Replace the missing values with a placeholder category indicating a missing value.
- D. Replace the missing values with the feature's mean.
Answer: D
NEW QUESTION # 37
A Machine Learning Specialist is packaging a custom ResNet model into a Docker container so the company can leverage Amazon SageMaker for training. The Specialist is using Amazon EC2 P3 instances to train the model and needs to properly configure the Docker container to leverage the NVIDIA GPUs.
What does the Specialist need to do?
- A. Build the Docker container to be NVIDIA-Docker compatible.
- B. Set the GPU flag in the Amazon SageMaker CreateTrainingJob request body.
- C. Bundle the NVIDIA drivers with the Docker image.
- D. Organize the Docker container's file structure to execute on GPU instances.
Answer: C
NEW QUESTION # 38
You are designing an ML recommendation model for shoppers on your company's ecommerce website. You will use Recommendations Al to build, test, and deploy your system. How should you develop recommendations that increase revenue while following best practices?
- A. Import your user events and then your product catalog to make sure you have the highest quality event stream
- B. Use the "Other Products You May Like" recommendation type to increase the click-through rate
- C. Because it will take time to collect and record product data, use placeholder values for the product catalog to test the viability of the model.
- D. Use the "Frequently Bought Together' recommendation type to increase the shopping cart size for each order.
Answer: D
Explanation:
Frequently bought together' recommendations aim to up-sell and cross-sell customers by providing product.
NEW QUESTION # 39
As the lead ML Engineer for your company, you are responsible for building ML models to digitize scanned customer forms. You have developed a TensorFlow model that converts the scanned images into text and stores them in Cloud Storage. You need to use your ML model on the aggregated data collected at the end of each day with minimal manual intervention. What should you do?
- A. Use the batch prediction functionality of Al Platform
- B. Create a serving pipeline in Compute Engine for prediction
- C. Use Cloud Functions for prediction each time a new data point is ingested
- D. Deploy the model on Al Platform and create a version of it for online inference.
Answer: A
Explanation:
https://cloud.google.com/ai-platform/prediction/docs/batch-predict
NEW QUESTION # 40
A Machine Learning Specialist trained a regression model, but the first iteration needs optimizing. The Specialist needs to understand whether the model is more frequently overestimating or underestimating the target.
What option can the Specialist use to determine whether it is overestimating or underestimating the target value?
- A. Area under the curve
- B. Confusion matrix
- C. Root Mean Square Error (RMSE)
- D. Residual plots
Answer: A
NEW QUESTION # 41
A manufacturing company has a large set of labeled historical sales data. The manufacturer would like to predict how many units of a particular part should be produced each quarter.
Which machine learning approach should be used to solve this problem?
- A. Random Cut Forest (RCF)
- B. Principal component analysis (PCA)
- C. Logistic regression
- D. Linear regression
Answer: A
NEW QUESTION # 42
You are a data scientist at an industrial equipment manufacturing company. You are developing a regression model to estimate the power consumption in the company's manufacturing plants based on sensor data collected from all of the plants. The sensors collect tens of millions of records every day. You need to schedule daily training runs for your model that use all the data collected up to the current date. You want your model to scale smoothly and require minimal development work. What should you do?
- A. Develop a custom TensorFlow regression model, and optimize it using Vertex AI Training.
- B. Develop a custom scikit-learn regression model, and optimize it using Vertex AI Training.
- C. Develop a regression model using BigQuery ML.
- D. Train a regression model using AutoML Tables.
Answer: D
NEW QUESTION # 43
A technology startup is using complex deep neural networks and GPU compute to recommend the company's products to its existing customers based upon each customer's habits and interactions. The solution currently pulls each dataset from an Amazon S3 bucket before loading the data into a TensorFlow model pulled from the company's Git repository that runs locally. This job then runs for several hours while continually outputting its progress to the same S3 bucket. The job can be paused, restarted, and continued at any time in the event of a failure, and is run from a central queue.
Senior managers are concerned about the complexity of the solution's resource management and the costs involved in repeating the process regularly. They ask for the workload to be automated so it runs once a week, starting Monday and completing by the close of business Friday.
Which architecture should be used to scale the solution at the lowest cost?
- A. Implement the solution using a low-cost GPU-compatible Amazon EC2 instance and use the AWS Instance Scheduler to schedule the task
- B. Implement the solution using AWS Deep Learning Containers and run the container as a job using AWS Batch on a GPU-compatible Spot Instance
- C. Implement the solution using Amazon ECS running on Spot Instances and schedule the task using the ECS service scheduler
- D. Implement the solution using AWS Deep Learning Containers, run the workload using AWS Fargate running on Spot Instances, and then schedule the task using the built-in task scheduler
Answer: D
NEW QUESTION # 44
A Data Engineer needs to build a model using a dataset containing customer credit card information How can the Data Engineer ensure the data remains encrypted and the credit card information is secure?
- A. Use AWS KMS to encrypt the data on Amazon S3 and Amazon SageMaker, and redact the credit card numbers from the customer data with AWS Glue.
- B. Use a custom encryption algorithm to encrypt the data and store the data on an Amazon SageMaker instance in a VPC. Use the SageMaker DeepAR algorithm to randomize the credit card numbers.
- C. Use an Amazon SageMaker launch configuration to encrypt the data once it is copied to the SageMaker instance in a VPC. Use the SageMaker principal component analysis (PCA) algorithm to reduce the length of the credit card numbers.
- D. Use an IAM policy to encrypt the data on the Amazon S3 bucket and Amazon Kinesis to automatically discard credit card numbers and insert fake credit card numbers.
Answer: C
Explanation:
Explanation/Reference: https://docs.aws.amazon.com/sagemaker/latest/dg/pca.html
NEW QUESTION # 45
You are a lead ML engineer at a retail company. You want to track and manage ML metadata in a centralized way so that your team can have reproducible experiments by generating artifacts. Which management solution should you recommend to your team?
- A. Store all ML metadata in Google Cloud's operations suite.
- B. Manage all relational entities in the Hive Metastore.
- C. Store your tf.logging data in BigQuery.
- D. Manage your ML workflows with Vertex ML Metadata.
Answer: A
NEW QUESTION # 46
You work for a toy manufacturer that has been experiencing a large increase in demand. You need to build an ML model to reduce the amount of time spent by quality control inspectors checking for product defects. Faster defect detection is a priority. The factory does not have reliable Wi-Fi. Your company wants to implement the new ML model as soon as possible. Which model should you use?
- A. AutoML Vision Edge mobile-versatile-1 model
- B. AutoML Vision Edge mobile-high-accuracy-1 model
- C. AutoML Vision model
- D. AutoML Vision Edge mobile-low-latency-1 model
Answer: C
NEW QUESTION # 47
......
Professional-Machine-Learning-Engineer Exam Practice Questions prepared by Google Professionals: https://actualtests.vceprep.com/Professional-Machine-Learning-Engineer-latest-vce-prep.html