
![]()
Free DP-600 Exam Study Guide for the NEW [Sep-2025] Dumps Test Engine
DP-600 PDF Dumps Extremely Quick Way Of Preparation
NEW QUESTION # 62
Hotspot Question
You have a Fabric tenant that contains a warehouse named WH1.
You have source data in a CSV file that has the following fields:
- SalesTransactionID
- SaleDate
- CustomerCode
- CustomerName
- CustomerAddress
- ProductCode
- ProductName
- Quantity
- UnitPrice
You plan to implement a star schema for the tables in WH1. The dimension tables in WH1 will implement Type 2 slowly changing dimension (SCD) logic.
You need to design the tables that will be used for sales transaction analysis and load the source data.
Which type of target table should you specify for the CustomerName, CustomerCode, and SaleDate fields? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Answer:
Explanation: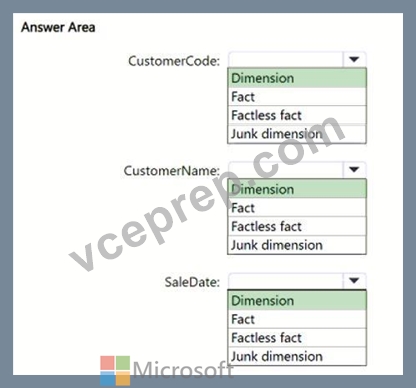
NEW QUESTION # 63
You need to ensure that Contoso can use version control to meet the data analytics requirements and the general requirements. What should you do?
- A. Modify the settings of the Research division workspaces to use an Azure Repos repository.
- B. Store all the semantic models and reports in Data Lake Gen2 storage.
- C. Modify the settings of the Research workspaces to use a GitHub repository.
- D. Store all the semantic models and reports in Microsoft OneDrive.
Answer: C
NEW QUESTION # 64
You have a Microsoft Fabric tenant that contains a dataflow.
You are exploring a new semantic model.
From Power Query, you need to view column information as shown in the following exhibit.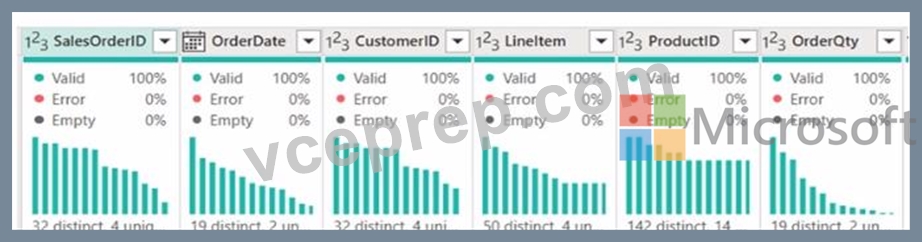
Which three Data view options should you select? Each correct answer presents part of the solution. NOTE: Each correct answer is worth one point.
- A. Show column quality details
- B. Enable details pane
- C. Enable column profile
- D. Show column profile in details pane
- E. Show column value distribution
Answer: A,B,C
Explanation:
To view column information like the one shown in the exhibit in Power Query, you need to select the options that enable profiling and display quality and distribution details. These are: A. Enable column profile - This option turns on profiling for each column, showing statistics such as distinct and unique values. B. Show column quality details - It displays the column quality bar on top of each column showing the percentage of valid, error, and empty values. E. Show column value distribution - It enables the histogram display of value distribution for each column, which visualizes how often each value occurs.
NEW QUESTION # 65
You need to resolve the issue with the pricing group classification.
How should you complete the T-SQL statement? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.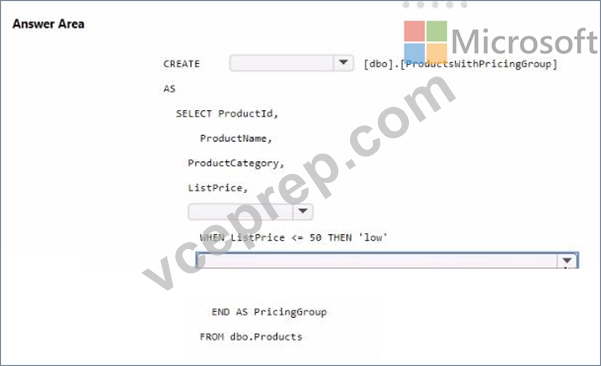
Answer:
Explanation: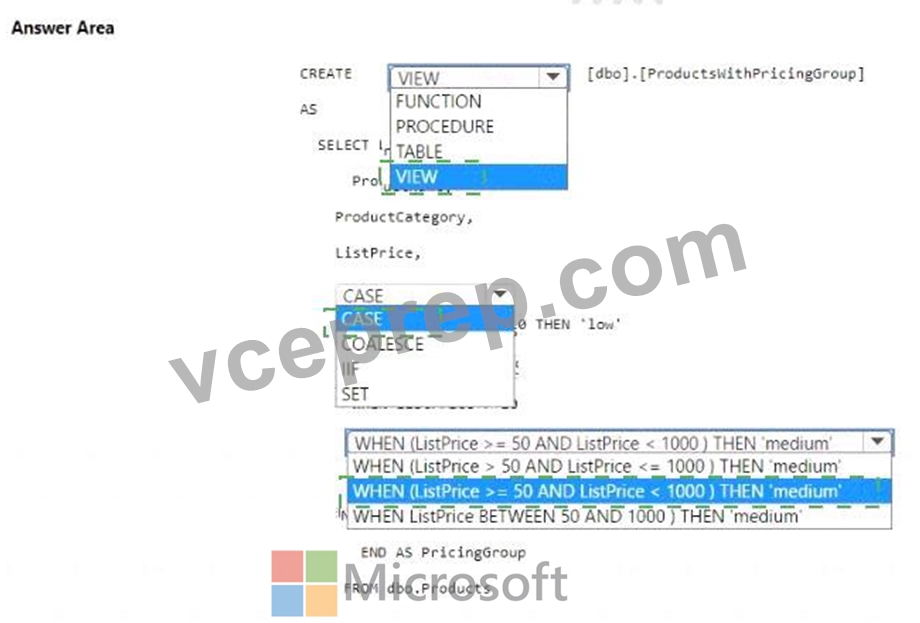
Explanation:
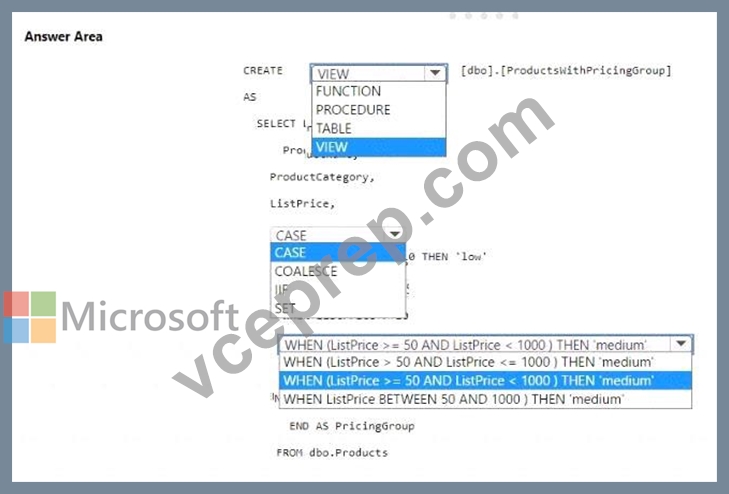
* You should use CREATE VIEW to make the pricing group logic available for T-SQL queries.
* The CASE statement should be used to determine the pricing group based on the list price.
The T-SQL statement should create a view that classifies products into pricing groups based on the list price.
The CASE statement is the correct conditional logic to assign each product to the appropriate pricing group.
This view will standardize the pricing group logic across different databases and semantic models.
NEW QUESTION # 66
You have a semantic model named Model 1. Model 1 contains five tables that all use Import mode. Model1 contains a dynamic row-level security (RLS) role named HR. The HR role filters employee data so that HR managers only see the data of the department to which they are assigned.
You publish Model1 to a Fabric tenant and configure RLS role membership. You share the model and related reports to users.
An HR manager reports that the data they see in a report is incomplete.
What should you do to validate the data seen by the HR Manager?
- A. Select Test as role to view the report as the HR manager,
- B. Filter the data in the report to match the intended logic of the filter for the HR department.
- C. Select Test as role to view the data as the HR role.
- D. Ask the HR manager to open the report in Microsoft Power Bl Desktop.
Answer: C
Explanation:
To validate the data seen by the HR manager, you should use the 'Test as role' feature in Power BI service.
This allows you to see the data exactly as it would appear for the HR role, considering the dynamic RLS setup. Here is how you would proceed:
* Navigate to the Power BI service and locate Model1.
* Access the dataset settings for Model1.
* Find the security/RLS settings where you configured the roles.
* Use the 'Test as role' feature to simulate the report viewing experience as the HR role.
* Review the data and the filters applied to ensure that the RLS is functioning correctly.
* If discrepancies are found, adjust the RLS expressions or the role membership as needed.
References: The 'Test as role' feature and its use for validating RLS in Power BI is covered in the Power BI documentation available on Microsoft's official documentation.
NEW QUESTION # 67
You have a Fabric tenant that contains two lakehouses.
You are building a dataflow that will combine data from the lakehouses. The applied steps from one of the queries in the dataflow is shown in the following exhibit.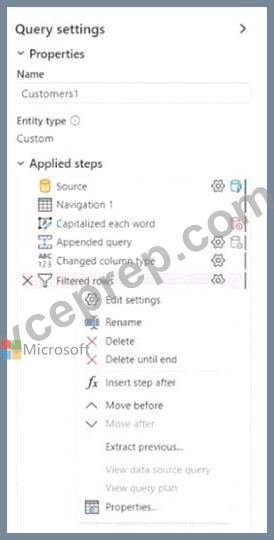
Use the drop-down menus to select the answer choice that completes each statement based on the information presented in the graphic. NOTE: Each correct selection is worth one point.
Answer:
Explanation:
Explanation:
Folding in Power Query refers to operations that can be translated into source queries. In this case, "some" of the steps can be folded, which means that some transformations will be executed at the data source level. The steps that cannot be folded will be executed within the Power Query engine. Custom steps, especially those that are not standard query operations, are usually executed within Power Query engine rather than being pushed down to the source system.
References =
* Query folding in Power Query
* Power Query M formula language
NEW QUESTION # 68
You have a Fabric tenant that contains a Microsoft Power Bl report named Report 1.
Report1 is slow to render. You suspect that an inefficient DAX query is being executed.
You need to identify the slowest DAX query, and then review how long the query spends in the formula engine as compared to the storage engine.
Which five actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
Answer:
Explanation: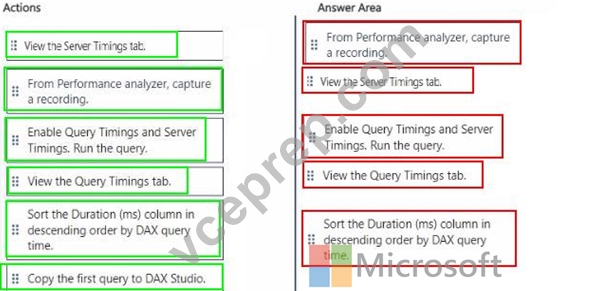
NEW QUESTION # 69
You need to design a semantic model for the customer satisfaction report.
Which data source authentication method and mode should you use? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.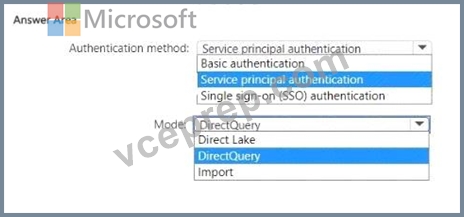
Answer:
Explanation: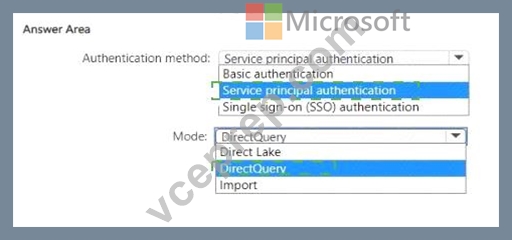
Explanation:
For the semantic model design required for the customer satisfaction report, the choices for data source authentication method and mode should be made based on security and performance considerations as per the case study provided.
Authentication method: The data should be accessed securely, and given that row-level security (RLS) is required for users executing T-SQL queries, you should use an authentication method that supports RLS.
Service principal authentication is suitable for automated and secure access to the data, especially when the access needs to be controlled programmatically and is not tied to a specific user's credentials.
Mode: The report needs to show data as soon as it is updated in the data store, and it should only contain data from the current and previous year. DirectQuery mode allows for real-time reporting without importing data into the model, thus meeting the need for up-to-date data. It also allows for RLS to be implemented and enforced at the data source level, providing the necessary security measures.
Based on these considerations, the selections should be:
* Authentication method: Service principal authentication
* Mode: DirectQuery
NEW QUESTION # 70
Hotspot Question
You have a Fabric tenant that contains two lakehouses.
You are building a dataflow that will combine data from the lakehouses. The applied steps from one of the queries in the dataflow is shown in the following exhibit.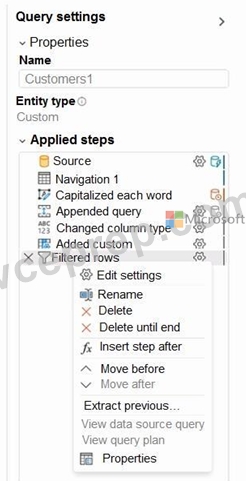
Use the drop-down menus to select the answer choice that completes each statement based on the information presented in the graphic.
NOTE: Each correct selection is worth one point.
Answer:
Explanation: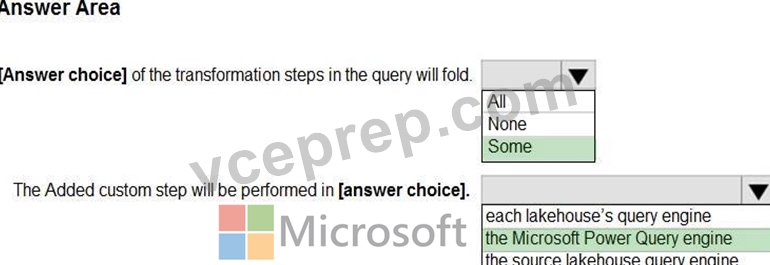
NEW QUESTION # 71
You have a Fabric workspace named Workspace1 and an Azure Data Lake Storage Gen2 account named storage"!. Workspace1 contains a lakehouse named Lakehouse1.
You need to create a shortcut to storage! in Lakehouse1.
Which connection and endpoint should you specify? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Answer:
Explanation:
Explanation:
When creating a shortcut to an Azure Data Lake Storage Gen2 account in a lakehouse, you should use the abfss (Azure Blob File System Secure) connection string and the dfs (Data Lake File System) endpoint. The abfss is used for secure access to Azure Data Lake Storage, and the dfs endpoint indicates that the Data Lake Storage Gen2 capabilities are to be used.
NEW QUESTION # 72
You have a Fabric tenant that contains a semantic model named Model1. Model1 uses Import mode. Model1 contains a table named Orders. Orders has 100 million rows and the following fields.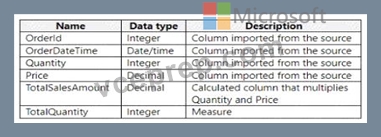
You need to reduce the memory used by Model! and the time it takes to refresh the model. Which two actions should you perform? Each correct answer presents part of the solution. NOTE: Each correct answer is worth one point.
- A. Convert Quantity into the Text data type.
- B. Replace TotalSalesAmount with a measure.
- C. Replace TotalQuantity with a calculated column.
- D. Split OrderDateTime into separate date and time columns.
Answer: B,D
Explanation:
To reduce memory usage and refresh time, splitting the OrderDateTime into separate date and time columns (A) can help optimize the model because date/time data types can be more memory-intensive than separate date and time columns. Moreover, replacing TotalSalesAmount with a measure (D) instead of a calculated column ensures that the calculation is performed at query time, which can reduce the size of the model as the value is not stored but calculated on the fly. References = The best practices for optimizing Power BI models are detailed in the Power BI documentation, which recommends using measures for calculations that don't need to be stored and adjusting data types to improve performance.
NEW QUESTION # 73
Case Study 2 - Litware, Inc
Overview
Litware, Inc. is a manufacturing company that has offices throughout North America. The analytics team at Litware contains data engineers, analytics engineers, data analysts, and data scientists.
Existing Environment
Fabric Environment
Litware has been using a Microsoft Power BI tenant for three years. Litware has NOT enabled any Fabric capacities and features.
Available Data
Litware has data that must be analyzed as shown in the following table.
The Product data contains a single table and the following columns.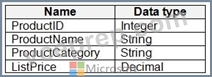
The customer satisfaction data contains the following tables:
- Survey
- Question
- Response
For each survey submitted, the following occurs:
- One row is added to the Survey table.
- One row is added to the Response table for each question in the survey.
- The Question table contains the text of each survey question. The third question in each survey response is an overall satisfaction score. Customers can submit a survey after each purchase.
User Problems
The analytics team has large volumes of data, some of which is semi-structured. The team wants to use Fabric to create a new data store.
Product data is often classified into three pricing groups: high, medium, and low. This logic is implemented in several databases and semantic models, but the logic does NOT always match across implementations.
Requirements
Planned Changes
Litware plans to enable Fabric features in the existing tenant. The analytics team will create a new data store as a proof of concept (PoC). The remaining Liware users will only get access to the Fabric features once the PoC is complete. The PoC will be completed by using a Fabric trial capacity The following three workspaces will be created:
- AnalyticsPOC: Will contain the data store, semantic models, reports pipelines, dataflow, and notebooks used to populate the data store
- DataEngPOC: Will contain all the pipelines, dataflows, and notebooks used to populate OneLake
- DataSciPOC: Will contain all the notebooks and reports created by the data scientists The following will be created in the AnalyticsPOC workspace:
- A data store (type to be decided)
- A custom semantic model
- A default semantic model
Interactive reports
The data engineers will create data pipelines to load data to OneLake either hourly or daily depending on the data source. The analytics engineers will create processes to ingest, transform, and load the data to the data store in the AnalyticsPOC workspace daily. Whenever possible, the data engineers will use low-code tools for data ingestion. The choice of which data cleansing and transformation tools to use will be at the data engineers' discretion.
All the semantic models and reports in the Analytics POC workspace will use the data store as the sole data source.
Technical Requirements
The data store must support the following:
- Read access by using T-SQL or Python
- Semi-structured and unstructured data
- Row-level security (RLS) for users executing T-SQL queries
Files loaded by the data engineers to OneLake will be stored in the Parquet format and will meet Delta Lake specifications.
Data will be loaded without transformation in one area of the AnalyticsPOC data store. The data will then be cleansed, merged, and transformed into a dimensional model The data load process must ensure that the raw and cleansed data is updated completely before populating the dimensional model The dimensional model must contain a date dimension. There is no existing data source for the date dimension. The Litware fiscal year matches the calendar year. The date dimension must always contain dates from 2010 through the end of the current year.
The product pricing group logic must be maintained by the analytics engineers in a single location. The pricing group data must be made available in the data store for T-SOL. queries and in the default semantic model. The following logic must be used:
- List prices that are less than or equal to 50 are in the low pricing group.
- List prices that are greater than 50 and less than or equal to 1,000 are in the medium pricing group.
- List prices that are greater than 1,000 are in the high pricing group.
Security Requirements
Only Fabric administrators and the analytics team must be able to see the Fabric items created as part of the PoC.
Litware identifies the following security requirements for the Fabric items in the AnalyticsPOC workspace:
- Fabric administrators will be the workspace administrators.
- The data engineers must be able to read from and write to the data store. No access must be granted to datasets or reports.
- The analytics engineers must be able to read from, write to, and create schemas in the data store. They also must be able to create and share semantic models with the data analysts and view and modify all reports in the workspace.
- The data scientists must be able to read from the data store, but not write to it. They will access the data by using a Spark notebook
- The data analysts must have read access to only the dimensional model objects in the data store. They also must have access to create Power BI reports by using the semantic models created by the analytics engineers.
- The date dimension must be available to all users of the data store.
- The principle of least privilege must be followed.
Both the default and custom semantic models must include only tables or views from the dimensional model in the data store. Litware already has the following Microsoft Entra security groups:
FabricAdmins: Fabric administrators
- AnalyticsTeam: All the members of the analytics team
- DataAnalysts: The data analysts on the analytics team
- DataScientists: The data scientists on the analytics team
- DataEngineers: The data engineers on the analytics team
- AnalyticsEngineers: The analytics engineers on the analytics team
Report Requirements
The data analysts must create a customer satisfaction report that meets the following requirements:
- Enables a user to select a product to filter customer survey responses to only those who have purchased that product.
- Displays the average overall satisfaction score of all the surveys submitted during the last 12 months up to a selected dat.
- Shows data as soon as the data is updated in the data store.
- Ensures that the report and the semantic model only contain data from the current and previous year.
- Ensures that the report respects any table-level security specified in the source data store.
- Minimizes the execution time of report queries.
Hotspot Question
You need to resolve the issue with the pricing group classification.
How should you complete the T-SQL statement? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.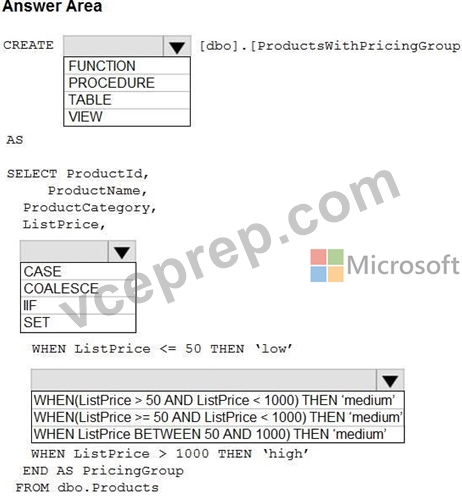
Answer:
Explanation: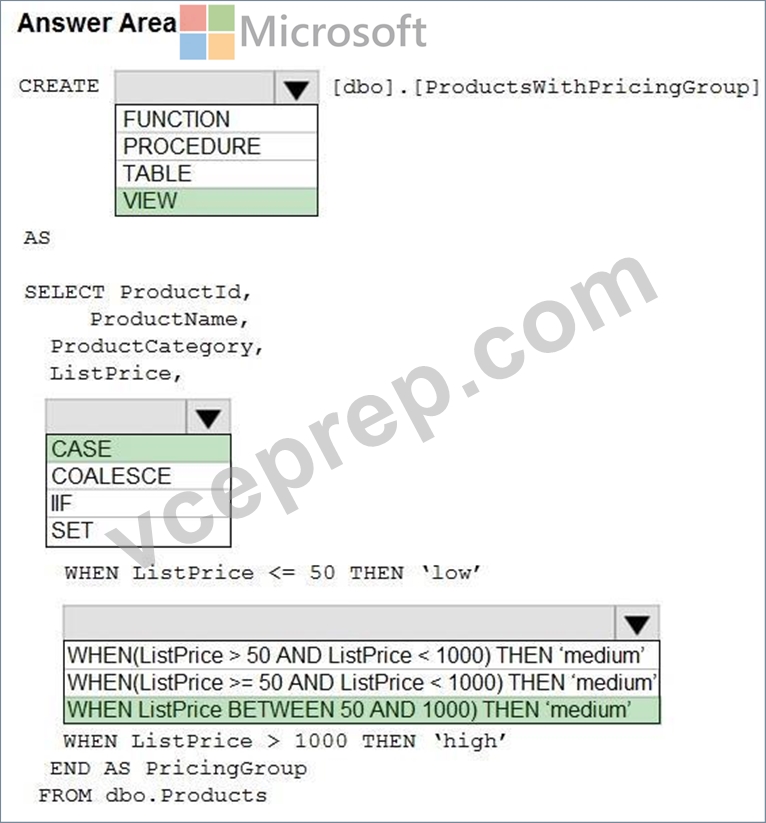
NEW QUESTION # 74
You have a Fabric tenant that contains a semantic model. The model contains data about retail stores.
You need to write a DAX query that will be executed by using the XMLA endpoint. The query must return the total amount of sales from the same period last year.
How should you complete the DAX expression? To answer, select the appropriate options in the answer are a. NOTE: Each correct selection is worth one point.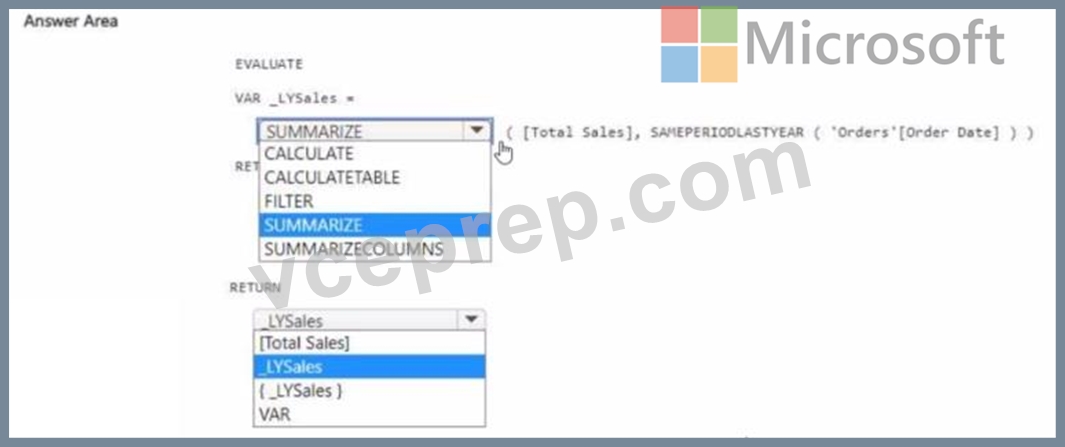
Answer:
Explanation: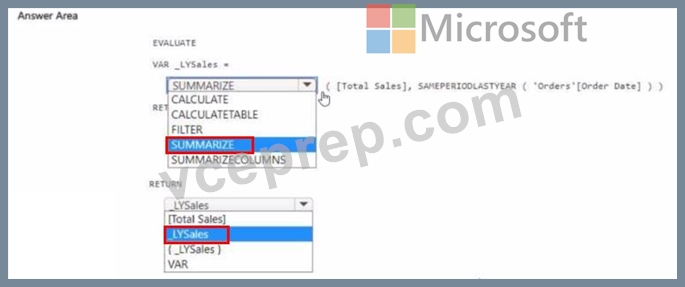
NEW QUESTION # 75
Note: This section contains one or more sets of questions with the same scenario and problem. Each question presents a unique solution to the problem. You must determine whether the solution meets the stated goals. More than one solution in the set might solve the problem. It is also possible that none of the solutions in the set solve the problem.
After you answer a question in this section, you will NOT be able to return. As a result, these questions do not appear on the Review Screen.
Your network contains an on-premises Active Directory Domain Services (AD DS) domain named contoso.com that syncs with a Microsoft Entra tenant by using Microsoft Entra Connect.
You have a Fabric tenant that contains a semantic model.
You enable dynamic row-level security (RLS) for the model and deploy the model to the Fabric service.
You query a measure that includes the USERNAME() function, and the query returns a blank result.
You need to ensure that the measure returns the user principal name (UPN) of a user.
Solution: You update the measure to use the USERPRINCIPALNAME() function.
Does this meet the goal?
- A. Yes
- B. No
Answer: A
NEW QUESTION # 76
You have a Fabric tenant tha1 contains a takehouse named Lakehouse1. Lakehouse1 contains a Delta table named Customer.
When you query Customer, you discover that the query is slow to execute. You suspect that maintenance was NOT performed on the table.
You need to identify whether maintenance tasks were performed on Customer.
Solution: You run the following Spark SQL statement:
EXPLAIN TABLE customer
Does this meet the goal?
- A. No
- B. Yes
Answer: A
Explanation:
No, the EXPLAIN TABLE statement does not identify whether maintenance tasks were performed on a table.
It shows the execution plan for a query. References = The usage and output of the EXPLAIN command can be found in the Spark SQL documentation.
NEW QUESTION # 77
You have a Fabric tenant that contains a takehouse named lakehouse1. Lakehouse1 contains a Delta table named Customer.
When you query Customer, you discover that the query is slow to execute. You suspect that maintenance was NOT performed on the table.
You need to identify whether maintenance tasks were performed on Customer.
Solution: You run the following Spark SQL statement:
DESCRIBE HISTORY customer
Does this meet the goal?
- A. Yes
- B. No
Answer: A
NEW QUESTION # 78
You have a Fabric warehouse that contains the following data.
The data has the following characteristics:
* Each customer is assigned a unique CustomerlD value.
* Each customer is associated to a single SalesRegion value.
* Each customer is associated to a single CustomerAddress value.
* The Customer table contains 5 million rows.
* All foreign key values are non-null.
You need to create a view to denormalize the data into a customer dimension that contains one row per distinct CustomerlD value. The solution must minimize query processing time and resources.
How should you complete the T-SQL statement? To answer, select the appropriate options in the answer area.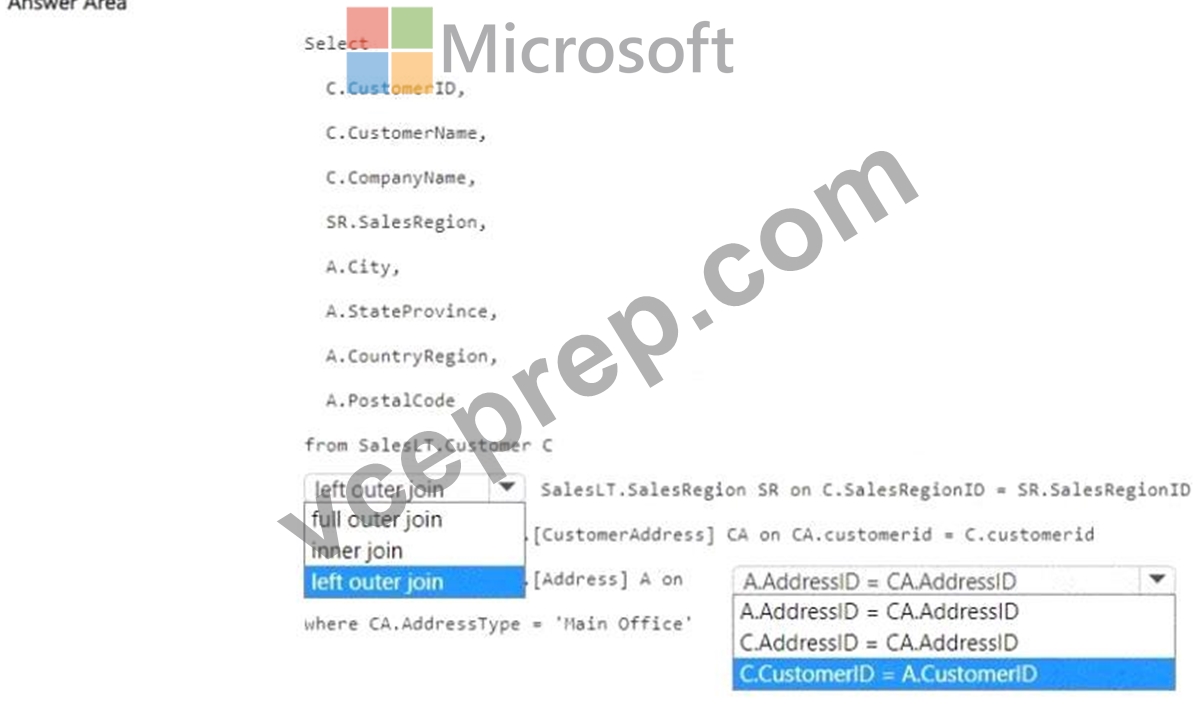
Answer:
Explanation: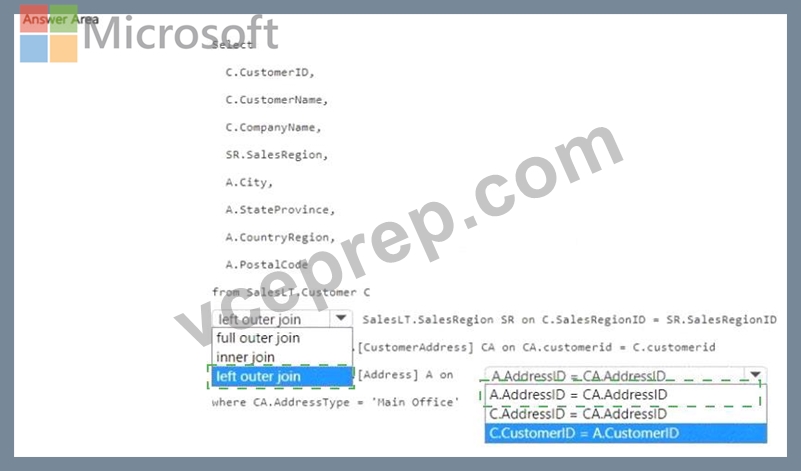
Explanation: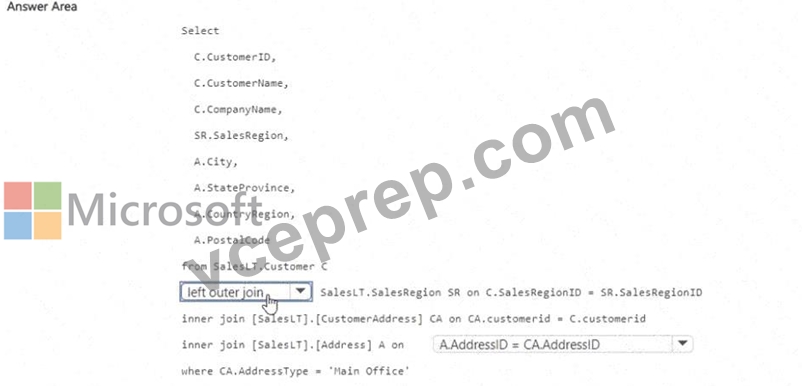
NEW QUESTION # 79
You need to design a semantic model for the customer satisfaction report.
Which data source authentication method and mode should you use? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.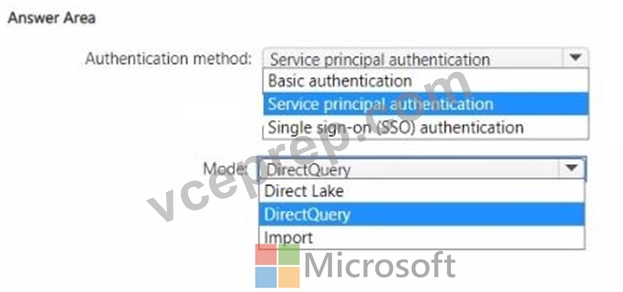
Answer:
Explanation: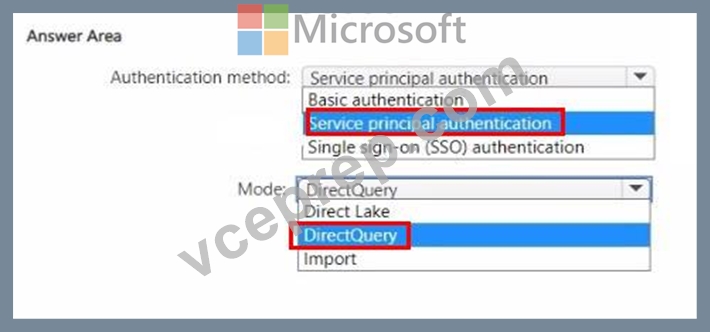
NEW QUESTION # 80
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You have a Fabric tenant that contains a new semantic model in OneLake.
You use a Fabric notebook to read the data into a Spark DataFrame.
You need to evaluate the data to calculate the min, max, mean, and standard deviation values for all the string and numeric columns.
Solution: You use the following PySpark expression: df.explain()
Does this meet the goal?
- A. No
- B. Yes
Answer: A
NEW QUESTION # 81
What should you recommend using to ingest the customer data into the data store in the AnatyticsPOC workspace?
- A. a Spark notebook
- B. a stored procedure
- C. a pipeline that contains a KQL activity
- D. a dataflow
Answer: D
Explanation:
For ingesting customer data into the data store in the AnalyticsPOC workspace, a dataflow (D) should be recommended. Dataflows are designed within the Power BI service to ingest, cleanse, transform, and load data into the Power BI environment. They allow for the low-code ingestion and transformation of data as needed by Litware's technical requirements. References = You can learn more about dataflows and their use in Power BI environments in Microsoft's Power BI documentation.
NEW QUESTION # 82
You have a Fabric tenant that contains a new semantic model in OneLake.
You use a Fabric notebook to read the data into a Spark DataFrame.
You need to evaluate the data to calculate the min, max, mean, and standard deviation values for all the string and numeric columns.
Solution: You use the following PySpark expression:
df.show()
Does this meet the goal?
- A. No
- B. Yes
Answer: A
Explanation:
The df.show() method also does not meet the goal. It is used to show the contents of the DataFrame, not to compute statistical functions. Reference = The usage of the show() function is documented in the PySpark API documentation.
NEW QUESTION # 83
You have a Microsoft Power Bl report named Report1 that uses a Fabric semantic model.
Users discover that Report1 renders slowly.
You open Performance analyzer and identify that a visual named Orders By Date is the slowest to render. The duration breakdown for Orders By Date is shown in the following table.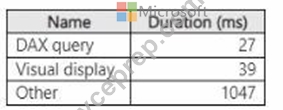
What will provide the greatest reduction in the rendering duration of Report1?
- A. Enable automatic page refresh.
- B. Optimize the DAX query of Orders By Date by using DAX Studio.
- C. Change the visual type of Orders By Dale.
- D. Reduce the number of visuals in Report1.
Answer: D
Explanation:
Based on the duration breakdown provided, the major contributor to the rendering duration is categorized as
"Other," which is significantly higher than DAX Query and Visual display times. This suggests that the issue is less likely with the DAX calculation or visual rendering times and more likely related to model performance or the complexity of the visual. However, of the options provided, optimizing the DAX query can be a crucial step, even if "Other" factors are dominant. Using DAX Studio, you can analyze and optimize the DAX queries that power your visuals for performance improvements. Here's how you might proceed:
* Open DAX Studio and connect it to your Power BI report.
* Capture the DAX query generated by the Orders By Date visual.
* Use the Performance Analyzer feature within DAX Studio to analyze the query.
* Look for inefficiencies or long-running operations.
* Optimize the DAX query by simplifying measures, removing unnecessary calculations, or improving iterator functions.
* Test the optimized query to ensure it reduces the overall duration.
References: The use of DAX Studio for query optimization is a common best practice for improving Power BI report performance as outlined in the Power BI documentation.
NEW QUESTION # 84
You have a Fabric tenant that contains a lakehouse.
You are using a Fabric notebook to save a large DataFrame by using the following code.
For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.
Answer:
Explanation:
Explanation:
* The results will form a hierarchy of folders for each partition key. - Yes
* The resulting file partitions can be read in parallel across multiple nodes. - Yes
* The resulting file partitions will use file compression. - No
Partitioning data by columns such as year, month, and day, as shown in the DataFrame write operation, organizes the output into a directory hierarchy that reflects the partitioning structure. This organization can improve the performance of read operations, as queries that filter by the partitioned columns can scan only the relevant directories. Moreover, partitioning facilitates parallelism because each partition can be processed independently across different nodes in a distributed system like Spark. However, the code snippet provided does not explicitly specify that file compression should be used, so we cannot assume that the output will be compressed without additional context.
References =
* DataFrame write partitionBy
* Apache Spark optimization with partitioning
NEW QUESTION # 85
......
Enhance your career with DP-600 PDF Dumps - True Microsoft Exam Questions: https://actualtests.vceprep.com/DP-600-latest-vce-prep.html